Banco de Dados
Um banco de dados SQL (Structured Query Language) é um sistema que armazena, organiza e gerencia dados em formato estruturado, usando tabelas com linhas e colunas. Ele permite que os dados sejam consultados, inseridos, atualizados e deletados por meio da linguagem SQL. É amplamente usado em aplicações web, sistemas corporativos e softwares em geral por sua confiabilidade e capacidade de lidar com grandes volumes de informação de forma eficiente.
O que é um Database ?
Um banco de dados é um sistema organizado para armazenar, gerenciar e recuperar dados eletrônicos de maneira eficiente. Ele consiste em tabelas, onde cada linha representa uma entrada e as colunas representam atributos. Bancos de dados são amplamente usados em diversas áreas para gerenciar grandes volumes de informações, facilitando a organização e recuperação de dados. Sistemas de gerenciamento de banco de dados (SGBD) são usados para facilitar a criação, manutenção e consulta desses bancos de dados.
Dados Estruturados e Não Estruturados
- Dados Estruturados: São dados organizados em uma estrutura predefinida, geralmente em tabelas com linhas e colunas. Cada valor tem um tipo específico e segue um esquema predefinido. Bancos de dados relacionais, onde as informações são organizadas em tabelas, são um exemplo comum de dados estruturados.
- Dados Não Estruturados: São dados que não seguem uma estrutura fixa ou organização prévia. Eles podem incluir texto livre, imagens, vídeos e outros formatos que não se encaixam facilmente em uma tabela. Redes sociais, e-mails, documentos em texto livre e mídias são exemplos de dados não estruturados. A análise desses dados geralmente requer métodos mais avançados, como processamento de linguagem natural para texto ou reconhecimento de padrões para imagens e vídeos.
Em resumo, dados estruturados seguem uma organização definida, enquanto dados não estruturados carecem dessa organização predefinida e podem assumir diversas formas. Ambos os tipos de dados são importantes, e a capacidade de lidar com ambos é fundamental em muitas aplicações de análise e tomada de decisão.
Tipos de Dados Primitivos
Comandos Mysql
Em um SGBD nós utilizamos de comandos para manipular dados, como inserções, edições ou visualizações, a seguir você irá aprender alguns dos comandos para manipular um banco de dados com o MySql Workbench.
Criar um database
-- Forma completa
CREATE DATABASE IF NOT EXISTS nomedodatabase
DEFAULT CHARACTER SET utf8
DEFAULT COLLATE utf8_general_ci;
-- Forma simplificada
CREATE DATABASE nomedodatabase;
Criar uma tabela
-- Forma simplificada
CREATE TABLE nomedatabela (
nome VARCHAR(30),
idade TINYINT(3),
sexo CHAR(1),
peso FLOAT,
nacionalidade VARCHAR(20),
);
-- Forma mais completa
CREATE TABLE nomedatabela (
id INT NOT NULL auto_increment,
nome VARCHAR(30) NOT NULL,
sexo ENUM('M','F'),
peso DECIMAL(5,2),
altura DECIMAL(3,2),
nacionalidade VARCHAR(20) DEFAULT 'Brasil',
PRIMARY KEY(id)
) DEFAULT CHARSET = utf8; Deletar tabela ou database
-- Deleta o banco de dados
DROP DATABASE nomedodatabase;
-- Deleta a tabela
DROP TABLE nomedatabela; Inserindo dados em uma tabela
-- Formato padrão
INSERT INTO nomedatabela
(id, nome, nascimento, sexo, peso, altura, nacionalidade)
VALUES
(DEFAULT, 'Thiago', '2003-01-04', 'M', '59.5', '1.70', 'Brasil');
-- A data precisa ser no formato YYYY-MM-DD
-- Forma simplificada porém os dados precisam estar na mesma sequência da tabela
INSERT INTO nomedatabela VALUES
(DEFAULT, 'Thiago', '2003-01-04', 'M', '59.5', '1.70', 'Brasil');
-- Inserindo mais de um dado por vez
INSERT INTO nomedatabela
(id, nome, nascimento, sexo, peso, altura, nacionalidade)
VALUES
(DEFAULT, 'Emanuelle', '2003-03-22', 'F', '62.3,' '1.62', 'Brasil'),
(DEFAULT, 'Andreza', '2004-04-11', 'F', '55.6', '1.59', 'Brasil'),
(DEFAULT, 'Thiago', '2003-01-04', 'M', '59.5', '1.70', 'Brasil');Descrevendo dados
DESCRIBE nomedatabela;
-- Formato simplificado
DESC nomedatabela; Alterando campos tabela
-- Adiciona a coluna no final da tabela
ALTER TABLE nomedatabela
ADD COLUMN nomedacoluna INT;
-- Formato simplificado
ALTER TABLE nomedatabela
ADD nomedacoluna INT;
-- Adiciona a coluna no início da tabela
ALTER TABLE nomedatabela
ADD COLUMN nomedacoluna INT FIRST;
-- Adiciona a coluna após a coluna informada
ALTER TABLE nomedatabela
ADD COLUMN nomedacoluna INT AFTER nomedeoutracoluna;
/* O modify reescreve toda a coluna ou seja, se você não passar todas as contraints,
ele irá deleta-las. (modify não muda o nome da coluna)
*/
ALTER TABLE nomedatabela
MODIFY COLUMN nomedacoluna VARCHAR(20) NOT NULL DEFAULT '';
-- Reescreve toda a coluna assim como o modify porém da a permissão de alterar o nome
ALTER TABLE nomedatabela
CHANGE COLUMN nomedacolunaatual nomedanovacoluna VARCHAR(20);
-- Esse comando é específico do MySQL. Em bancos como PostgreSQL ou SQL Server, o comando seria diferente.
-- Altera o nome da tabela
ALTER TABLE nomedatabela
CHANGE TO novonome;Alterando dados da tabela
-- Altera os dados da tabela onde a chave primária é igual a 1
UPDATE nomedatabela
SET nomedocampo = 'Thiago', nomedocampo2 = '2003-01-04'
WHERE chaveprimaria = '1';
-- Deleta o registro de chave primária 1
DELETE FROM nomedatabela
WHERE chaveprimaria = '1';
-- Deleta todos os dados de uma tabela porém mantém sua estrutura
TRUNCATE TABLE nomedatabela;Utilizando o select
--Seleciona todos os campos da tabela
SELECT * FROM nomedatabela;
--Order by ordena pelo parâmetro passado, nesse caso, ordena pelo nome em ordem ascendente A-Z, 1-2
SELECT * FROM nomedatabela ORDER BY nome;
--Order by ordena pelo parâmetro passado nesse caso, ordena pelo nome em ordem descentente Z-A, 2-1
SELECT * FROM nomedatabela ORDER BY nome DESC;
--Seleciona tudo que atenda a condição no where
SELECT * FROM nomedatabela WHERE id = '13';
SELECT * FROM nomedatabela WHERE ano >= '2016' AND carga > '40';
SELECT * FROM nomedatabela WHERE ano >= '2016' OR carga > '40';
/* Pode receber diversos operadores lógicos, os mais comuns são: =, !=, <, >, <=, >=,
porém também existem o and, or e o in.
*/
-- O like procura por algo que inclua o que passano no parâmetro
SELECT * FROM nomedatabela WHERE nome LIKE 'silva';
--O notlike é o contrário do like, procura por registros que não incluam o que foi passado por parâmetro
SELECT * FROM nomedatabela WHERE nome NOT LIKE 'silva';
/* Existem 2 "coringas" para usar no select com o like, o "%" e o "_"
O "%" significa que pode ou não ter algo antes ou depois da palavra, seu uso depende da
sua localização, como nos exemplos:
*/
--Irá buscar por tudo que termine com "silva"
SELECT * FROM nomedatabela WHERE nome LIKE '%silva';
--Irá buscar por tudo que começe com "silva"
SELECT * FROM nomedatabela WHERE nome LIKE 'silva%';
--Irá buscar por tudo que inclua "silva" em qualquer lugar
SELECT * FROM nomedatabela WHERE nome LIKE '%silva%';
-- Procura o que estiver entre as duas condições
SELECT nome, ano FROM nomedatabela WHERE ano BETWEEN 2020 AND 2024;
-- Seleciona tudo porém mostra somente 1 vez as linhas duplicadas
SELECT DISTINCT nacionalidade FROM nomedatabela;
-- Retorna a quantidade de items encontrados
SELECT COUNT(*) FROM nomedatabela;
--Retorna o maior valor encontrado
SELECT MAX(totalaulas) FROM cursos WHERE ano = '2016';
--Retorna o menor valor encontrado
SELECT nome, MIN(totalaulas) FROM cursos WHERE ano = '2016';
--Retorna a soma dos valores
SELECT SUM(totalaulas) FROM cursos;
--Retorna a média dos valores
SELECT AVG(totalaulas) FROM cursos;Relacionamentos, entidades e chaves
Relacionamentos
Um relacionamento de tabelas é uma conexão estabelecida entre duas ou mais tabelas em um banco de dados relacional. Esses relacionamentos permitem que os dados sejam vinculados e consultados de forma eficiente, permitindo uma melhor organização e estruturação dos dados.
Existem diferentes tipos de relacionamentos de tabelas, como o relacionamento 1 para 1 e o relacionamento 1 para muitos. No relacionamento 1 para 1, cada registro em uma tabela está associado a apenas um registro correspondente na outra tabela, já no relacionamento 1 para muitos, um registro em uma tabela pode estar associado a vários registros correspondentes em outra tabela, mas cada registro na segunda tabela está associado a apenas um registro na primeira tabela.
Esses relacionamentos são estabelecidos usando chaves primárias e chaves estrangeiras. A chave primária é um atributo único em uma tabela que identifica exclusivamente cada registro. A chave estrangeira é um atributo em uma tabela que faz referência à chave primária de outra tabela. Essas chaves são usadas para conectar os dados entre as tabelas, permitindo consultas complexas que combinam informações de várias tabelas.
Os relacionamentos de tabelas são fundamentais para a modelagem de dados em um banco de dados relacional, pois permitem a representação de vínculos entre os dados e a obtenção de informações mais completas e precisas por meio de consultas.
Entidades
Um conceito fundamental em SQL é o de entidades. Em um contexto de bancos de dados, uma entidade representa uma tabela, que é uma coleção de registros relacionados. Cada registro em uma tabela representa uma entrada individual de dados. As entidades são usadas para organizar e armazenar dados de maneira estruturada e eficiente.
No SQL, as entidades são criadas usando o comando CREATE TABLE, onde são definidos os nomes das colunas e os tipos de dados que cada coluna pode armazenar. As entidades também podem ser modificadas usando o comando ALTER TABLE, que permite adicionar, modificar ou excluir colunas de uma tabela existente.
As entidades são a base para a criação e manipulação de dados em um banco de dados SQL, permitindo a organização, recuperação e análise eficiente dos dados armazenados.
Atributos SQL
No SQL os atributos são basicamente as colunas de uma tabela. Cada atributo corresponde a um tipo de dado específico, como texto, número, data, entre outros. Os atributos definem a estrutura da tabela e determinam quais tipos de valores podem ser armazenados em cada coluna.
Os atributos têm propriedades, como restrições de integridade e valores padrão. As restrições de integridade garantem que os dados inseridos nas colunas estejam dentro de limites específicos, como valores mínimos e máximos. Os valores padrão especificam um valor predefinido que será inserido automaticamente em uma coluna se nenhum valor for fornecido durante a inserção de dados.
Os atributos desempenham um papel fundamental na definição da estrutura e organização dos dados em um banco de dados SQL. Eles fornecem informações sobre os tipos de dados que podem ser armazenados, as restrições aplicadas a esses dados e os relacionamentos entre as tabelas.
Chaves primárias e estrangeiras
Os atributos podem ter chaves primárias e estrangeiras. A chave primária identifica exclusivamente cada registro em uma tabela e garante a integridade dos dados. As chaves estrangeiras estabelecem relacionamentos entre tabelas, permitindo que os dados sejam conectados e consultados de maneira eficiente.
As tabelas podem ter relacionamentos uns com os outros por meio de chaves estrangeiras, que são colunas que fazem referência a uma chave primária em outra tabela. Esses relacionamentos permitem a criação de consultas complexas que combinam dados de várias tabelas. Os relacionamentos entre entidades são fundamentais para modelar e representar a estrutura e os vínculos dos dados em um banco de dados relacional.
Relacionamento 1 para 1
Um relacionamento 1 para 1 ocorre quando uma entidade está diretamente relacionada a apenas uma outra entidade. Isso significa que cada registro de uma entidade está associado a apenas um registro da outra entidade. Em outras palavras, para cada registro em uma tabela, há um único registro correspondente na tabela relacionada. Esse tipo de relacionamento é útil quando há uma dependência direta entre as entidades e é necessário garantir que cada registro tenha uma correspondência única no relacionamento.
Relacionamento 1 para N
Um relacionamento 1 para n, ou um relacionamento um para muitos, ocorre quando uma entidade está diretamente relacionada a várias instâncias de outra entidade. Nesse tipo de relacionamento, um registro em uma tabela pode estar associado a vários registros correspondentes em outra tabela, mas cada registro na segunda tabela está associado a apenas um registro na primeira tabela. Esse tipo de relacionamento é comumente utilizado para representar situações em que um único objeto ou entidade está relacionado a várias instâncias de outra entidade. Por exemplo, um cliente pode ter várias ordens de compra, mas cada ordem de compra está vinculada a apenas um cliente. Esse tipo de relacionamento é fundamental para modelar e representar a estrutura dos dados em bancos de dados relacionais.
Relacionamento N para N
Um relacionamento N para N, ou um relacionamento muitos para muitos, ocorre quando uma entidade está diretamente relacionada a várias instâncias de outra entidade e vice-versa. Nesse tipo de relacionamento, vários registros em uma tabela podem estar associados a vários registros correspondentes em outra tabela. Esse tipo de relacionamento é comumente utilizado para representar situações em que várias entidades estão interligadas de forma complexa. Por exemplo, em um sistema de gerenciamento de estudantes e disciplinas, vários estudantes podem se inscrever em várias disciplinas, e cada disciplina pode ter vários estudantes matriculados. Para modelar esse relacionamento, é necessário criar uma tabela intermediária que registre as associações entre as entidades, armazenando os identificadores das entidades relacionadas. Esse tipo de relacionamento é fundamental para representar a estrutura dos dados em bancos de dados relacionais e permite consultas e análises avançadas envolvendo múltiplas entidades interligadas.
Usando chaves estrangeiras e Joins
Chaves estrangeiras
Para cadastrar uma chave estrangeira em uma tabela, primeiro precisamos identificar a relação como diz acima, 1 para 1, 1 para N ou então N para N , feito isso seguimos as seguintes regras:
- 1 para 1
No relacionamento 1 para 1, colocamos a chave estrangeira na outra entidade, como no exemplo abaixo:

- 1 para N
No relacionamento 1 para N, colocamos a chave estrangeira sempre no lado N, como no exemplo:
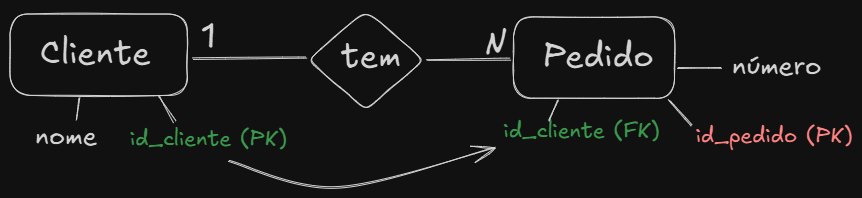
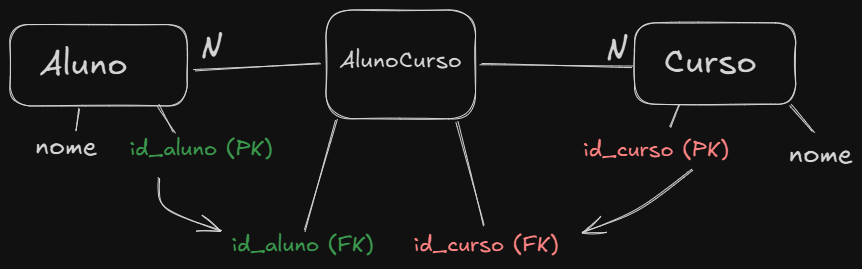
- N para N
O relacionamento N para N é um pouco mais complexo, precisamos criar outra entidade entre as duas que estamos relacionando e liga-las, como no exemplo abaixo:
Na prática, ligamos tabelas com chaves estrangeiras dessa maneira:
-
Primeiro criamos o campo da chave estrangeira na tabela seguindo as regras acima, lembrando que o campo precisa ser da mesma formatação, porém não precisa ser do mesmo nome.
ALTER TABLE alunos ADD column cursopreferido INT; -
Logo após, configuramos a nova coluna como chave estrangeira.
ALTER TABLE alunos ADD foreing KEY (cursopreferido) REFERENCES cursos(idcurso); -- Configurando o campo como chave estrangeira do campo idcurso da tabela cursos.
Feito isso o campo já estará configurado como uma chave estrangeira!
Utilizando o Join
O inner join e o outer join são operações comuns usadas para combinar dados de várias tabelas em consultas SQL.
-
Inner Join
O inner join é usado para retornar apenas os registros que têm correspondência em ambas as tabelas envolvidas na junção. Ele combina os registros com base em uma condição de correspondência especificada na cláusula ON. A consulta resultante incluirá apenas os registros que satisfazem a condição de junção. Por exemplo, se tivermos uma tabela de "clientes" e uma tabela de "pedidos", um inner join entre elas retornaria apenas os clientes que fizeram pedidos.
Para utiliza-lo fazemos o seguinte comando:
SELECT c.nome, p.numero FROM clientes AS c INNER JOIN pedidos AS p ON c.idcliente = p.idcliente; -- Basicamente retorna os dados que tiverem relação, ou seja, só irá mostrar os clientes que tiverem um pedido.💡 O
ASé utilizado para “apelidar” uma tabela, assim facilitando na hora de escrever.
-
Outer Join
O outer join é usado para retornar todos os registros de uma tabela, mesmo que não haja correspondência na tabela relacionada. Existem três tipos de outer join: left outer join, right outer join e full outer join. O left outer join retorna todos os registros da tabela da esquerda e os registros correspondentes da tabela da direita. O right outer join retorna todos os registros da tabela da direita e os registros correspondentes da tabela da esquerda. O full outer join retorna todos os registros de ambas as tabelas, incluindo os registros que não têm correspondência na tabela relacionada.
Para utiliza-lo fazemos o seguinte comando:
SELECT c.nome, p.numero FROM clientes AS c LEFT OUTER JOIN pedidos AS p ON c.idcliente = p.idcliente; -- Retorna todos os dados da tabela direcionada(left, righ, full) mais as relações da outra tabela.
💡 Tanto no
INNER JOINcomo noOUTER JOIN, as palavrasINNEReOUTERsão opcionais, porém noOUTER JOIN, precisa-se referenciar a direção, left, right ou full.
A utilização dessas operações de junção permite combinar dados de várias tabelas em consultas SQL, fornecendo informações mais completas e precisas para análise e tomada de decisão.